前言:Intel正式发布全新酷睿处理器
泡泡网CPU频道1月5日 时光飞逝,新的一年到来了。我们还来不及回味着过去一年里发生了什么的时候,前方耀眼的光芒却已吸引着我们朝它望去。在2011年的伊始,有一颗重磅炸弹已经袭来,未必绝后,但已堪称空前。没错,Intel全新架构的处理器产品---全新一代酷睿i系列处理器于今日正式发布。
这次新产品的发布,包含桌面及移动版本共29款处理器、10款芯片组,相关产品超过500款。数量和规模超越了Intel过去任何一次新产品发布。
本文中,你将会阅读到以下内容:
第一章 Intel酷睿系列的出现和产品回顾
第一章/第一节 酷睿架构大变身 酷睿一代
第一章/第二节 酷睿二代真正发力!一二代对比(1)
第一章/第三节 酷睿二代真正发力!一二代对比(2)
第一章/第四节 三大领域跨平台!酷睿2性能提升40%
第一章/第五节 酷睿2的黄金岁月!新奔腾再续辉煌 第一章/第六节 酷睿i系列到来!高端用户首选i7
第一章/第七节 丰富产品线!LGA1156接口酷睿i系列第二章 Intel处理器微架构和核心代号解析
第二章/第一节 Intel处理器微架构和核心代号解析
第二章/第二节 回顾:Bloomfield核心首次整合内存控制器
第二章/第三节 回顾:Lynnfield核心首次整合PCI-E总线控制器
第二章/第四节 回顾:Clarkdale核心CPU首次整合GPU
第二章/第五节 SandyBridge核心:首次原生整合GPU核心 第三章 SandyBridge核心架构解析
第三章/第一节 SandyBridge核心架构改进总览
第三章/第二节 SandyBridge架构解析:指令缓存和分支预测
第三章/第四节 SandyBridge架构解析:新增AVX高级矢量扩展指令集
第三章/第五节 SandyBridge架构解析:新增物理寄存文件
第三章/第六节 SandyBridge架构:环形总线与三级缓存
第三章/第七节 SandyBridge架构:革命性的整合GPU
第三章/第八节 SandyBridge架构:内置多媒体处理器
第三章/第九节 SandyBridge架构:更加给力的睿频加速技术第四章 SandyBridge处家族介绍
第四章/第一节 SandyBridge家族产品定位与布局
第四章/第二节 SandyBridge家族产品命名规则及特点
第四章/第三节 SandyBridge桌面版本处理器规格表
第四章/第四节 SandyBridge移动版本处理器规格表
第四章/第五节 SandyBridge处理器精美图赏第五章 P67/H67芯片组解析&产品曝光
第五章/第一节 6系与5系芯片组的差异
第五章/第二节 主板PCH升级为PCI-Express 2.0
第五章/第三节 不再提供对PCI设备的支持
第五章/第四节 加入SATA 6Gbps支持
第五章/第五节:Intel原厂主板解析:DH67-BL
第五章/第六节:Intel原厂主板解析:DP67-BG
第五章/第七节 昂达魔剑P67规格详解
第五章/第八节 华擎P67 Extreme4规格详解
第五章/第九节 华擎Fatal1ty P67规格详解
第五章/第十节 华硕P8P67 Deluxe规格详
第五章/第十节 技嘉GA-P67A-UD4规格详解
第五章/第十一节 技嘉GA-P67A-UD3R规格详解
第五章/第十二节 技嘉GA-P67A-UD7规格详解
第五章/第十三节 捷波悍马HI08规格曝
第五章/第十四节 精英P67H2-A规格详解
第五章/第十五节 微星P67A-GD65规格详解
第五章/第十六节 七彩虹战旗C.P67 X5规格详解
第五章/第十七节 映泰TP67XE规格详解
第五章/第十八节 富士康H67MP-S规格详解
第五章/第十九节 华硕P8H67-M EVO规格详解
第五章/第二十节 技嘉GA-H67A-UD2H规格详解
第五章/第二十一节 精英H67H2-M规格详解
第五章/第二十二节 七彩虹战旗C.H67 X5规格详解
第五章/第二十三节 索泰H67 ITX U3 WIFI规格详解
第五章/第二十四节 映泰TH67+规格详解第六章 CPU性能测试
第六章/第一节 CPU性能测试说明
第六章/第二节 CPU基准:SuperPI
第六章/第三节 CPU基准:wPRIME 第六章/第四节 CPU基准:Fritz
第六章/第五节 CPU性能:SisoftWare Sandra
第六章/第六节 内存性能:Everest & Sisoftware Sandra
第六章/第七节 CPU渲染:Cine Bench
第六章/第八节 文件压缩:WinRAR
第六章/第九节 视频转码:Media Coder
第六章/第十节 3D渲染:Maya2009
第六章/第十一节 3D渲染:3DS MAX 2010
第六章/第十二节 综合性能:PCMark Vantage
第六章/第十三节 3DMark Vantage
第六章/第十四节 游戏:使命召唤7
第六章/第十五节 游戏:星际争霸2
第六章/第十六节 游戏:文明5第七章 GPU性能测试
第七章/第一节 3DMark 06
第七章/第二节 街头霸王4
第七章/第三节 波斯王子5
第七章/第四节 使命召唤7
第七章/第五节 3DMark Vantage
第七章/第六节 孤岛危机
第七章/第七节 冲突世界
第七章/第八节 孤岛惊魂2
第七章/第九节 战地:叛逆连队2
第七章/第十节 失落的星球2
第七章/第十一节 地铁2033
第七章/第十二节 鹰击长空
第七章/第十三节 魔兽世界
第七章/第十四节 黑暗虚空
第七章/第十五节 文明5
第七章/第十六节 英雄连
第七章/第十七节 Media Espresso转码
第七章/第十八节 Media Converter转码第八章 功耗测试和性能对比
第八章/第一节 CPU功耗测试
第八章/第二节 GPU功耗测试
第八章/第三节 CPU性能对比:i7 2600K vs i7 870
第八章/第四节 CPU性能对比:i5 2500K vs i5 760
第八章/第五节 CPU性能对比:i3 2100 vs i3 530
第八章/第六节 GPU性能对比:HD2000 vs GMA HD
第八章/第七节 GPU性能对比:HD3000 vs HD4250
第八章/第八节 GPU性能对比:HD3000 vs HD5450第九章 全文总结
第九章/第一节 编辑测试感受
第九章/第二节 全文总结&展望未来 酷睿架构大变身 酷睿一代
第一章 Intel酷睿系列的出现和产品回顾第一章/第一节 酷睿架构大变身 酷睿一代 泡泡网CPU频道1月5日 纵观Intel现在的产品线,主流的产品系列按照酷睿i3/i5/i7划分,最高端的处理器是六核的酷睿i7-990X,而入门级的市场则还存在Core 2处理器以及转为经济型的奔腾、赛扬系列。
酷睿系列处理器在市场驰骋多年
可以看到其中的奔腾系列处理器充当了重要的角色。其实Intel的奔腾系列处理器在酷睿一代推出前就已经在市场驰骋了12年之久,不过随着技术的发展和竞争的加剧,Intel之后推出了全新的酷睿系列处理器,不过推出的一代产品只是用于移动计算机,在上市不久后就被Core2取代。
酷睿i7-990X
老旧的Pentium M和Pentium 4 NetBurst架构已经不能满足处理器发展的需要,较高的功耗和发热量严重限制了处理器性能的提升,Intel随后推出的“酷睿”架构是在当时乃至现在(现有处理器仍是基于酷睿架构)都领先的节能微架构,该架构着眼于提高每瓦特性能,可以提供卓越的性能和能效。
酷睿二代真正发力!一二代对比(1)
第一章/第二节 酷睿二代真正发力!一二代对比(1) 酷睿一代处理器只面向移动平台出现,产品代号为Yonah,代表性的处理器为Core Solo T1300和T1400,以及Core Duo T2300-T2700,采用酷睿一代处理器的笔记本也有不少型号可以选择,比如宏碁的Travel Mate 3XXX和4XXX系列就是用了Core Duo T2XXX系列处理器。
Core Duo双核处理器只面向移动平台
不久后也就是在2006年7月,Intel就全球同步发布了代号Conroe和Merom的新一代台式机和笔记本处理器,包括Core 2 Duo和Core 2 Extreme两个品牌。其中在移动平台也就是Merom系列处理器的代表型号为Core 2 Duo T5500和T5600,稍高端的代表为Core 2 Duo T7200和T7400。
Merom与Yonah处理器规格对比
新一代的Merom处理器实际上仍是由Yonah改进而来——其中近90%设计是后者的改良,当时Intel声称全新Core微架构整合Mobile架构的省电高效率及上代桌面Netburst的功能,并为多核心应用作出优化。尽管改动不是很大,但是仍有不少亮点的改动,架构和线路得到重新改良,而且加入了5项重要改革——Intel Wide Dynmaic Execution、Intel Intelligent Power Capability、Intel Advanced Smart Cache、Intel Smart Memory Access及Intel Advanced Digital Media Boost。
酷睿二代真正发力!一二代对比(2)
第一章/第三节 酷睿二代真正发力!一二代对比(2) Merom处理器虽然是基于Yonah核心,但是实现了对Yonah的多个关键部分的强化,而且有七成的架构和线路得到重新设计,下面我们来看一下一些重大的改进。
首先得到改进的是处理器的缓存部分,除了缓存容量由一代的2MB提升至4MB(高端)外,缓存的结构也大大增强。Merom处理器每个核心都内建32KB一级指令缓存与32KB一级数据缓存,2个核心的一级数据缓存之间可以直接传输数据。另外核心内部采取共享式二级缓存设计,大大提高了两个核心的内部数据交换效率。
Core 2加入了EM64T的支持
其次,在指令集层面Merom处理器也得到大幅增强,每个核心内建4组指令解码单元,支持微指令融合与宏指令融合技术,每个时钟周期最多可以解码5条X86指令,并拥有改进的分支预测功能。每个核心内建5个执行单元子系统,执行效率非常高。另外Merom处理器加入了对EM64T与SSE4指令集的支持,可以使系统拥有更大的内存寻址空间,并大幅提升了视频处理器等性能。
其他方面也得到了加强,Intel Merom处理器具有了更好的电源管理功能;支持Intel VT技术和硬件防病毒功能;内建数字温度传感器;提供功率报告和温度报告等。
三大领域跨平台!酷睿2性能提升40%
第一章/第四节 三大领域跨平台!酷睿2性能提升40% 相比酷睿一代只在移动计算机平台出现,不久后也就是2006年5月初的酷睿2代可以说是Intel的真正发力,因为这一系列处理器横跨了桌面、笔记本和服务器三大领域,对应的产品代号分别为Conroe、Merom和Woodcrest。
酷睿2处理器至今仍硬朗
在性能上,酷睿2处理器可以说是处理器能效的大幅提升。酷睿架构相比原来的Pentium M和Pentium 4 NetBurst架构,大幅减少了功耗和发热量,在走出单纯追逐高主频的死胡同后,新架构的性能得到了大幅提升,而酷睿2代在加入了对64位技术的支持和增大了指令长度并提高了二级缓存容量后,相比第一代再次提高了约20%的性能,而比上一代则提升了40%。
Core 2 Duo在单个芯片上封装了多达2.91亿个晶体管,相比Pentium 4单核心、核心代号为Cedar Mill的处理器(包括631、641、651)封装的1.88亿,晶体管数量上增加了1亿个还要多,但是功耗却下降了40%,性能上据称也提升了40%。
酷睿2的黄金岁月!新奔腾再续辉煌
第一章/第五节 酷睿2的黄金岁月!新奔腾再续辉煌 酷睿2处理器是非常优秀的一代产品,从06年发布至今不少型号仍然在处理器市场很硬朗,产品的惊人生命周期要得益于它的高效率和低能耗。
关于高效率的说法,可以这么打个比方,早期的Core 2 Duo T7200处理器在超至2.64GHz时,一百万位的Super PI可以跑到20秒,而这个成绩需要NetBurst架构的Pentium 4处理器超频到6GHz。
奔腾系列处理器转为性价比级
另外新一代处理器还加入了对Intel的VT、EIST、EM64T和XD技术的支持,并且其中的高端型号加入了SSE4指令集,这一指令集可以大幅提升多媒体性能,理想情况下相比不支持这一指令集的处理器,相关性能提升了100%。
在这一优秀架构支持下,酷睿2处理器的产品线很丰富。最初的型号为面向桌面的E6000系列和面向移动平台的T7000和T5000系列。后来为丰富市场,Intel又推出了E4000系列。
奔腾E5200成为经典型号
提到Intel处理器的产品线或者提到CPU的型号不得不提的是Intel奔腾系列处理器,而在Core 2时代,于2008年下半年上市的奔腾E5200就是其中的一个奇葩。当时的奔腾系列处理器已经转为性价比级的产品。凭借优秀的超频性能和新一代架构的高效率,奔腾处理器恢复了以往的辉煌。
酷睿i系列到来!高端用户首选i7
第一章/第六节 酷睿i系列到来!高端用户首选i7 2008年11月18日,Intel发布了酷睿i7处理器——Core i7 920、Core i7 940和Core i7 965。这一系列处理器在当时点爆了高端用户的热情,因为据2008年英特尔技术峰会(IDF2008)展示,Core i7处理器的性能在当时最高端的Core 2 Extreme QX9770的三倍左右。
酷睿i7-920
Core i7 920、Core i7 940和Core i7 965的默认主频分别为2.66GHz、2.93GHz和3.2GHz,在Turbo技术支持下分别可以自动超至2.93GHz、3.2GHz和3.46GHz。该批处理器采用了45nm原生四核设计,拥有多达8MB三级缓存,并且支持三通道DDR3内存。超线程技术再次回归(奔腾4处理器出现过),并且发展到第二代。
先进的Nehalem微架构
Core i7处理器基于先进的Nehalem微架构设计,首批发布的三款处理器采用了四核八线程设计,当时还传言会出现8核心版本,相比Core2处理器加入了SSE4.2指令集,并且支持Turbo Mode自动超频技术(当时的称谓,目前多称为第一代睿频技术),摒弃了FSB前端总线设计,改用QPI总线,并且集成了三通道DDR3内存控制器,可以实现更大的数据吞吐,此外在虚拟技术、能源管理上都进一步得到了加强。
丰富产品线!LGA1156接口酷睿i系列
第一章/第七节 丰富产品线!LGA1156接口酷睿i系列 随着处理器市场的竞争,Intel逐步将高端的酷睿i系列处理器推向主流市场,因此继LGA1366接口的酷睿i7之后,2009年第三季度LGA1156的酷睿i5系列处理器开始走向市场,其中的代表性产品为酷睿i5-750和酷睿i7-860。
酷睿i5-750
Core i5处理器仍然是基于Nehalem架构,不过相比LGA 1366的Core i7系列在结构上做了一些改动。首先三通道DDR3内存支持变为双通道DDR3内存,此外首次将PCI-E控制器内部集成,这也就意味着传统的北桥被吞并,CPU直接通过以前联接北桥与南桥的DMI来与南桥交换数据。
按照Intel的TICK-TOCK策略,去年3月份,Intel在于北京召开的IDF2010技术峰会上发布了采用了32nm全新制程的Corei7/i5/i3处理器,其中酷睿i3-530的发布意味深远,因为该处理器首度集成了GPU显示芯片。
酷睿i3处理器首度集成GPU
相比四核心的酷睿i5处理器,酷睿i3-530系列采用双核四线程设计,三级缓存也精简为4MB,此外的内存控制器、双通道、睿频智能加速技术得到了保留。
Intel处理器微架构和核心代号解析
第二章 Intel处理器微架构和核心代号解析 Intel当初把新一代处理器命名为Core i7/i5/i3三大系列的本意是好的,让普通用户只看处理器型号就能了解其定位,但每个系列里面又有着架构完全不同、性能差距也不小的处理器类型,这导致产品划分比较混乱。现在Intel的SandyBridge微架构处理器也沿用了Core i7/i5/i3的命名方式,这无疑使得整条产品线变得更加复杂。
产品命名是一方面,Intel处理器的微架构以及核心代号也比较混乱,很多时候让人感到丈二和尚摸不着头脑,现在Intel一口气推出了多款新品,笔者认为很有必要将产品命名、微架构、核心代号来详细解读一番。
第二章/第一节 Intel处理器微架构和核心代号解析●
处理器微架构——Nehalem、Westmere、SandyBridge 首先来看看处理器的微架构,上代Core i系列处理器都是基于Nehalem微架构而设计的,但Intel将45nm工艺制造的Core i处理器命名为Nehalem架构,而32nm工艺的处理器微架构有一些改进,因此改称为Westmere架构。
Westmere相比Nehalem的改进有二:一是制造工艺从45nm升级到32nm,二是加入新的AES加密解密指令集。可以看出两者并没有本质的不同。
SandyBridge则是Intel全新的微架构,它使用了日渐成熟的32nm工艺,这就是Intel的著名的Tick-Tock战略。“Tick”代表着工艺的提升、晶体管变小,并在此基础上增强原有的微架构,而“Tock”则在维持相同工艺的前提下,进行微架构的革新,这样在制程工艺和核心架构的两条提升道路上,总是交替进行,一方面避免了同时革新可能带来的失败风险,同时持续的发展也可以降低研发的周期,并可以对市场造成持续的刺激,并最终提升产品的竞争力。
当然基于SandyBridge微架构下、使用更先进工艺制造的CPU则被称为IVY Bridge架构,这就比较遥远了。至于SandyBridge微架构相比Westmere有何改进,三言两语是说不清楚的,后文中将会为大家做详细的解读。
●
处理器核心代号——Bloomfield、Lynnfield、Clarkdale、Gulftown 微架构目前就三种,但每一种微架构下面又分为不同的处理器核心,他们都拥有自己独一无二的核心代号。
其中基于45nm Nehalem架构的有Bloomfield和Lynnfield两颗核心,基于32nm Westmere架构的有Clarkdale和Gulftown两颗核心。Gulftown其实就是Bloomfield的六核心版本,因为使用了32nm工艺,才被归入Westmere微架构。
至于SandyBridge微架构的处理器,今天发布的产品同样拥有两颗处理器核心(双核心和四核心),但Intel尚未公布这两颗核心的代号,目前的核心代号暂时都被称作是SandyBridge。
Bloomfield核心:首次整合内存控制器
Intel将新一代的SandyBridge处理器称作是第二代Core架构微处理器,因此在详细介绍SandyBridge处理器的核心架构之前,我们有必要对第一代Core架构微处理器做一个详细的回顾,这样才能深入了解Intel近年来是如何改良处理器微架构的。
第一代Core架构微处理器分为三个版本:Bloomfield、Lynnfield、Clarkdale(六核心版的Gulftown与Bloomfield没有本质不同,因此不做介绍),这三颗CPU核心一颗比一颗的集成度高,下面我们就一一解读:
第二章/第二节 回顾:Bloomfield核心首次整合内存控制器 2008年10月,Intel正式发布了Nehalem架构的Core i7 965/940/920三款处理器以及X58芯片组,这是Intel第一款整合内存控制器和QPI总线的产品,因此备受关注。
i7 9XX系列处理器是基于Nehalem架构的首款产品,核心研发代号是Bloomfield,采用了45nm工艺制造,是原生四核心设计,集众多先进技术于一身:
1. 超线程技术回归,四核八线程大幅提升CPU的多任务和多线程计算能力;
2. 整合三通道DDR3内存控制器,带宽大幅提升、延迟大大下降,从此内存不再是瓶颈;
3. QPI总线取代FSB总线,用以连接北桥芯片,Core 2架构最大的瓶颈被消除;
4. 采用大容量共享式三级缓存设计,较少数据等待延迟,多核应用效率提升。
i7 9XX系列的主要特点:四核心、八线程、三通道、三级缓存
★
配套芯片组X58+ICH10R,接口类型LGA1366 与之搭配的芯片组,只有X58这一款。X58芯片组为传统的南北桥设计,北桥通过QPI总线与CPU相连,内部整合了36条PCI-E 2.0通道,可以灵活的分配为两条x16或者四条x8插槽,供多显卡使用。
而南桥方面使用的依然是P45芯片组当中的ICH10R,通过DMI总线与北桥相连,基本功能相信大家都比较熟悉,就不再赘述。
★
Bloomfield核心Core i7 9XX系列CPU的特点总结: 四核八线程、三通道内存还有可以支持多显卡互联的X58芯片组,这些就是Bloomfield核心Core i7 9XX系列CPU的主要特点。
三通道内存带来的不仅是很高的内存带宽,更重要的是六条插槽全插满的话,可以支持最大12/24GB的海量内存容量,这对有特殊需求的用户很有吸引力。
X58北桥是此前整合了最多PCI-E 2.0通道的芯片组,对于需要强大游戏性能或者通用计算性能的用户来说,自然是插越多显卡越好,因此X58是这类用户的不二之选。
总的来说,i7 9XX搭配X58,是Intel为追求顶级性能玩家提供的终极选择,虽然它无论CPU主板还是内存都价值不菲,而且功耗很大,但除此之外别无它选。
Lynnfield核心:首次整合PCI-E控制器
第二章/第三节 回顾:Lynnfield核心首次整合PCI-E总线控制器 Bloomfield核心的Core i7 9XX系列虽然性能强大、功能完备,但由于X58主板和三条内存成本太高,难以普及。于是Intel准备推出简化版的Lynnfield核心,这就是Core i7 8XX和i5 7XX系列。
Lynnfield核心示意图
Lynnfield相比Bloomfield,在处理器内核部分几乎没有任何改动,同样是45nm工艺、原生四核心设计、支持超线程(仅限i7)、三级缓存容量也保持8MB,它也整合了内存控制器和QPI总线,但删去了一条内存通道,成为主流的双通道设计,QPI总线也删去了一条,仅保留一条。
Lynnfield与Bloomfield的L1/L2/L3完全相同
事实上,对于大多数普通用户来说,三通道内存的带宽过剩,因此删去一条之后,性能并没有多少损失。另外Bloomfield内置的两条QPI总线是给多CPU互联之用,而在民用市场基本完全闲置,只有一条QPI总线用来连接北桥,因此删掉一条没有任何影响。
简化成双通道之后,Lynnfield的针脚数量和封装面积缩小不少
Bloomfield已经整合了传统北桥最重要的功能——内存控制器,所以X58北桥当中就只剩下了PCI-E控制器。Lynnfield核心由于定位较低一些,考虑到大多数主流用户并不需要多显卡互联,因此Intel索性将北桥当中剩余的模块——PCI-E控制器简化之后(只有16条通道),全都整合在了CPU当中。
正因为整合了PCI-E控制器的关系,Lynnfield的晶体管数以及核心面积都要比Bloomfield大,所以Core i7 8XX处理器的售价比相近频率的Core i7 9XX还要贵。好在P55主板要比X58便宜,而且双通道内存显然比三通道便宜,另外不支持超线程技术的i5 7XX售价还算厚道,因此很受欢迎。
★ 配套芯片组P55,接口类型LGA1156
通过Intel官方Lynnfield核心示意图来看,处理器与芯片组之间居然没有使用QPI、而是通过DMI总线相连。要知道QPI总线带宽高达25GB/s,而DMI仅有2GB/s。
Intel官方的这张示意图让很多人产生误解
事实上在Lynnfield核心内部,除了整合了内存控制器外,Intel连PCI-E控制器也整合了进去(因此上图显卡直接与CPU相连),这就相当于整颗北桥都被CPU吃掉了,连接CPU与北桥的QPI总线自然也不会幸免。如此一来,CPU将直接与“南桥”相连,他们之间的总线叫做DMI。
也就是说,Lynnfield内部还是整合了QPI总线的,虽然只有一条,这一条QPI总线用以连接CPU核心部分与PCI-E控制器部分。Bloomfield核心的QPI总线频率可以随便超,而Lynnfield核心的QPI被锁定,其实没有任何关系,因为QPI的唯一用途就是连接北桥,内存走的是直连通道已经不经过QPI总线了,因此超频QPI不会有什么性能提升。
P55是单芯片设计的芯片组,其本质上就是一颗南桥,功能和ICH10R没有太大区别,既不支持SATA3.0也不支持USB3.0,而且南桥中的PCI-E通道是落后的1.0版本。要知道Lynnfield核心内部整合的PCI-E 2.0通道只有16条,只能满足单显卡或者双显卡的需要,此时如果用户有需要使用高速的扩展设备(比如USB3.0扩展卡)的话,P55南桥提供的PCI-E 1.0接口就成为了最大瓶颈。
★
Lynnfield核心Core i7 8XX和i5 7XX系列CPU的特点总结: 在CPU核心部分,Lynnfield与Bloomfield可以说没有任何区别,它最大的特点就是外围模块:双通道DDR3内存、整合PCI-E控制器,只支持双x8带宽的双卡互联。
i7 8XX和i5 7XX的唯一区别是超线程,i5被人为的屏蔽了HT功能,四核心四线程,并行计算性能损失不少,但单核效能不变,因此非常适合游戏玩家。
由于CPU整合了整颗北桥的关系,P55芯片组其实就是一颗南桥芯片,再加上少了一条内存通道,因此Lynnfield+P55平台的整体功耗要比Bloomfield+X58平台低很多。
整套平台成本较低、加上超低的功耗和发热,Lynnfield+P55平台成为了主流中高端玩家最喜爱的配置。
Clarkdale核心:CPU首次整合GPU
第二章/第四节 回顾:Clarkdale核心CPU首次整合GPU 显然,四核心的Lynnfield还不够亲民,主流市场依然是双核心的天下,所以双核心的Clarkdale诞生了,这颗核心也拥有很多亮点:首次使用32nm工艺、首次整合GPU,但其架构非常特殊,不同于之前的任何一款产品。
★
Clarkdale核心:双芯片封装、内置GPU设计Clarkdale核心处理器封装示意图
Clarkdale核心包括CPU和GPU两个部分,CPU部分使用了新一代32nm工艺制造,是双核心四线程设计;GPU部分就是传统意义上的北桥,为45nm工艺制造,内含双通道DDR3内存控制器、PCI-E控制器和集成显卡。
Clarkdale的北桥(GPU)和CPU部分示意图
CPU部分和GPU部分是各自独立的,微观上通过QPI总线相连,宏观上被封装在了一起,接口是与Lynnfield相同的LGA1156。整体上来看Clarkdale不仅整合了内存控制器和PCI-E控制器,还整合了显示核心,看似更加先进。
透过这张架构图,就可以更清楚的认识Clarkdale的互联架构
实际上它的这种架构与Core 2时代的G45没有本质区别,只不过G45的北桥(GPU)在主板上,而Clarkdale的北桥被转移到了CPU内部。也就是说,Clarkdale的内存控制器并没有被真正整合在CPU核心内部,而是在北桥当中,需要透过QPI总线传输数据,这与Bloomfield/Lynnfield直连的内存控制器有本质区别,这样做的结果导致Clarkdale的内存带宽和延迟相比Core 2提升不大——显然,这不是整合内存控制器产品应有的性能表现。
而且QPI带宽仅仅能够满足双通道DDR3-1333内存带宽的要求,没有富裕的带宽用来传输CPU和GPU之间还有其它设备的数据,因此以往Core 2平台上的FSB瓶颈依然存在。表面上看,Clarkdale什么都整合了,可实际上,它什么都没有整合。
★
核心微架构升级:从Nehalem到Westmere 在CPU部分,Intel将新一代32nm工艺的处理器核心架构命名为Westmere,Westmere架构相比Nehalem架构其实并没有多少改进,唯一的变化就是提供了7组新指令集的支持,分别是6组AES指令集和1组Carryless Multiply指令,主要用于加密、解密运算。
Clarkdale的特点:双核心、四线程、4MB L3、AES指令集、整合显卡
Clarkdale的CPU部分为双核心四线程设计,一、二级缓存没有变化,但三级缓存减少至4MB,显然双核心不需要像四核心那样超大容量的L3。减少L3的好处就是节约大量晶体管,成本和功耗发热都得到了很好的控制。
★
配套芯片组H55,接口LGA1156 由于都采用了LGA1156接口,Lynnfield和Clarkdale是可以共用芯片组的,但如果想要使用Clarkdale内置的集成显卡的话,就必须使用H55芯片组,因为只有H55才支持FDI通道,用来输出显示信号:
所以,H55和P55最大的区别就是能否支持FDI,其它南桥功能上的删减都是无关紧要的。
另外,Lynnfield和Clarkdale内置的PCI-E 2.0通道虽然都是16条,但Lynnfield可以被拆分为两个x8通道支持双卡互联,而Clarkdale不能被拆分只能支持单个独立显卡。
如此一来,Clarkdale处理器搭配P55主板的话,即便主板提供了两条PCI-E插槽也不能支持双卡互联,而且内置显卡无法使用。因此Clarkdale的最佳搭档还是H55。
★ Clarkdale核心Core i5 6XX和i3 5XX系列CPU的特点总结:
由于Clarkdale核心的内存控制器、集成显卡、PCI-E控制器都在北桥里面,CPU与北桥虽然被封装在了一起,而且使用了新一代的QPI总线,但是瓶颈依然存在,导致内存性能和GPU性能并不理想(但相比上代Core 2平台改进还是很明显的)。
不过,由于CPU部分使用了32nm工艺,北桥部分使用了45nm工艺(AMD的北桥还是65nm/55nm),因此Clarkdale搭配H55平台的整体功耗再创新低。而且由于CPU和北桥被封装在了一起,散热问题更容易解决,所以Clarkdale+H55成为了HTPC用户和入门级用户的最爱。
Clarkdale核心目前有Core i5 6XX和i3 5XX两个产品线,它们之间最主要的区别就是i5支持睿频智能加速技术,默认频率较高而且可以自动超频,而i3默认频率较低且不支持睿频,但超线程技术得以保留。当然两者的价格也差很多,总的来说i3性价比超高,在中低端大受欢迎。
SandyBridge核心:首次原生整合GPU核心
第二章/第五节 SandyBridge核心:首次原生整合GPU核心 Clarkdale核心虽然将CPU和GPU首次封装在了CPU基板上面,但本质上它并没有做到CPU和GPU的融合,竞争对手AMD认为Intel这种方式其实是“胶水”整合,他们自己的APU才是真正意义上的“融合”。
与雷声大雨点小的AMD不同,Intel做事从来都是脚踏实地、按部就班的走,在AMD的APU还停留在实验室阶段之时,Intel发布了首颗真正将CPU和GPU整合到一颗芯片上面的处理器,这就是今天我们要评测的重点产品——SandyBridge。
毫无疑问,SandyBridge相对于上代的Clarkdale来说,最大的改进就是将GPU部分真正融入了CPU核心内部,这样GPU部分也使用了先进的32nm工艺,并且可以充分利用CPU部分的大容量三级缓存以及低延迟的内存控制器,共享内存带宽,从而让集显部分获得可观的性能提升。
GPU处理单元和CPU核心被整合在了一颗芯片上面
除了CPU和GPU真正无缝整合在一起之外,Intel还对CPU与GPU两大处理器核心分别做了优化与改进,获得更高的指令执行效率,此外整合内存控制器相比上代产品带宽将更高、延迟会更低。
优化的核心、智能的频率控制、以及单一32nm工艺的核心,SandyBridge相比上代产品速度更快、功率更小,处理器效能被提升到新的境界!
SandyBridge核心架构改进总览
第三章 SandyBridge处理器核心架构解析第三章/第一节 SandyBridge核心架构改进总览 Intel Core i系列处理器拥有一套革命性的体系架构,包括大容量完全共享式的三级缓存、整合的内存控制器以及QPI快速互联总线。无论是Nehalem、Westmere还是最新的SandyBridge微架构,其CPU部分的架构是基本相同的,改进的只是处理器指令集以及外围功能和控制模块。
从Nehalem到Westmere,制造工艺从45nm进化到32nm,新增AES加密解密指令集,Turbo Boost睿频加速技术升级,从原来的多核+1倍频单核+2倍频、增强至多核+2倍频单核+4倍频。
从Westmere到SandyBridge,制造工艺没有变化,但CPU+GPU的整合模式有了革命性的改进,两者之间不再通过QPI总线互联,而是将GPU的运算单元作为处理器内核的一部分,GPU可以直接使用CPU的三级缓存以及内存控制器,将CPU和GPU相互通讯时的延迟降到了最低。
SandyBridge处理器模块示意图
由于GPU嵌入到了CPU内核当中,所以三级缓存以及内存控制器的共享和负载平衡算法都需要做相应的改进,SandyBridge的微架构相比上代改变是巨大的。Intel声称新的三级缓存和内存控制器相比上代产品无论带宽还是延迟都有了不小的进步,以满足CPU和GPU双方运算单元的存取需要。
SandyBridge处理器架构与功能简介
此外,SandyBridge新增的AVX(Advanced Vector Extension)高级矢量扩展指令集并不是一般意义上的指令集扩充,它需要对CPU和GPU的运算单元底层寄存器重新设计,从而获得更强的浮点运算能力,从根本上改进CPU浮点运算能力较弱、图形和视频处理消耗资源过大的现状,后文中笔者会详细介绍AVX指令集的威力。
当然,SandyBridge的Turbo Boost睿频加速技术也升级到了2.0版本,与Westmere微架构相比,自动超频幅度更大,对于负载的判定更加准确,而且可以智能的分配CPU和GPU的负载,同时对CPU和GPU进行超频。
SandyBridge架构:指令缓存和分支预测
第三章/第二节 SandyBridge架构解析:指令缓存和分支预测 从高级层面角度看,SandyBridge架构只是一次进化,但是如果看看Nehalem/Westmere以来晶体管变化的规模,绝对是一次革命。
Core 2引入了一种叫作循环流检测器(LSD)的逻辑块,检测到CPU执行软件循环的时候就会关闭分支预测器、预取/解码引擎,然后通过自身缓存的微指令(micro-ops)供给执行单元。这种做法通过在循环执行的时候关闭前端节省了功耗,并改进了性能。Core i系列处理器沿用了这种设计。
SandyBridge里面又增加了一个微指令缓存,用于在指令解码时临时存放。这里没有什么严格的算法,指令只要在解码就会放入缓存。预取硬件获得一个新指令的时候,会首先检查它是否存在于微指令缓存中,如是则由缓存为其余的管线服务,前端随之关闭。解码硬件是x86管线里非常复杂的部分,关闭它能够节约大量的功耗。
这个缓存是直接映射的,能存储大约1.5K微指令,相当于6KB指令缓存。它位于一级指令缓存内,大多数程序的命中率都能达到80%左右,而且带宽也相比一级指令缓存更高、更稳定。真正的一级指令和数据缓存并没有变,仍然都是32KB,合计64KB。这看起来有点儿像Pentium 4的追踪缓存,但最大的不同是它并不缓存追踪,而更像是一个指令缓存,存储的是微指令,而非x86指令(macro-ops)。
与此同时,Intel还完全重新了一个分支预测单元(BPU),精确度更高,并在三个方面进行了创新。
第一,标准的BPU都是2-bit预测器,每个分支都使用相关可信度(强/弱)进行标记。Intel发现,这种双模预测器所预测的分支几乎都是强可信度的,因此SNB里多个分支都使用一个可信度位,而不是每个分支对应一个可信度位,结果就是在分支历史表中同样的位可以对应更多分支,进而提高预测精确度。
第二,分支目标同样做了翻新。之前的架构中分支目标的大小都是固定的,但是大多数目标都是相对近似的。SNB现在支持多个不同的分支目标大小,而不是一味扩大寻址能力、保存所有分支目标,因而浪费的空间更少,CPU能够跟踪更多目标、加快预测速度。
第三,提高分支预测器精度的传统方法是使用更多的历史位,但这只对要求长指令的特定类型分支有效,SNB于是将分支按照长短不同历史进行划分,从而提高预测精度。
SandyBridge架构:AVX高级矢量扩展指令
第三章/第四节 SandyBridge架构解析:新增AVX高级矢量扩展指令集 Westmere相比Nehalem,唯一的改进就是新增AES加密解密指令集,在特定应用下速度提升非常显著,但由于一般人很少用到加密和解密应用,因此这一改进几乎可以被忽视了。
现在SandyBridge相比Westmere,在AES指令集的基础上,又新增了AVX(高级矢量扩展)指令集,这个指令集就非同一般了,Intel打算用它来逐步取代已经服役几十年的SSE(单指令多数据流式扩展)指令集,AVX指令集的重要性可见一斑!
所谓的矢量,就是带有方向的标量……在数学上的表现就是多个参数的代数式,也就是多个标量的集合。为了更好地表示多个标量,AVX高级矢量扩展将原有的128位浮点指令扩展到了256位,可以同时处理8个32位(4字节)的浮点数或者一个256位的数:

AVX指令集是和SandyBridge微架构紧密结合的,因此,微架构的浮点寄存器也要从128位扩展到256位,此外,Load单元也要适应一次载入256位的能力,SandyBridge没有直接扩展原有Load单元的位宽,而是通过增加了一个Load单元来达到256bit Load的能力,如下图所示:
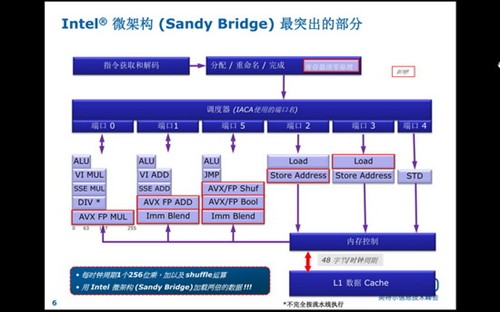
可以看到,在0、1、5端口都增加了256位宽度AVX指令执行单元。
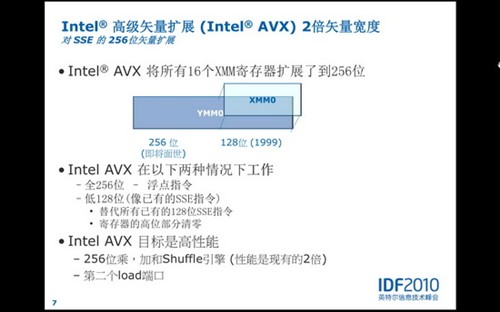


最后,Intel提到了,由于128位SSE指令与256位AVX指令位宽不同,在混合编码的时候,指令切换需要进行额外的寄存器高位保留操作,因此混用SSE/AVX将会导致性能损失。应尽量向新指令集进行迁移。
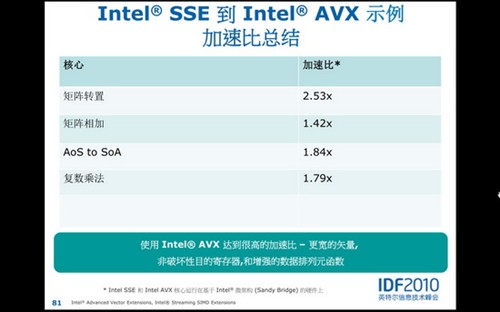
最后,Intel给出了在如前所述的4种常见运算下的AVX指令集加速比(AVX vs SSE over Sandy Bridge)。可以看出,在硬件环境不变的情况下,如果软件支持AVX指令集的话,速度提升可达1.5-2.5倍之多!

看来Intel是铁定决心要改进CPU的浮点运算能力,SandyBridge的下一代IVYBridge将会新增FMA指令集,FMA是同时进行一个乘法和一个加法的运算,在图形操作上很是常见,相信关注GPU图形技术的朋友们已经会比较熟悉。看得出来未来的处理器,CPU与GPU之间的界限将会非常模糊了。
SandyBridge架构:新增物理寄存文件
第三章/第五节 SandyBridge架构解析:新增物理寄存文件 Physical Reg File(PRF,物理寄存文件)的引入是SandyBridge微架构的一大特色,这是Nehalem架构所不具备的。当然AMD新一代的推土机和山猫架构也会支持,AMD很早之前就公布了架构细节,现在Intel首次将其应用在了实际产品当中。
在Core 2和Nehalem架构中,每个微指令需要的每个操作数都有一份拷贝,这就意味着乱序执行硬件(调度器/重排序缓存/关联队列)必须要非常大,以便容纳微指令和相关数据。Core Duo时代是80-bit,加入SSE指令集后增至128-bit,现在又有了AVX指令集,按照趋势会翻番至256-bit。
PRF在寄存器文件中存储微指令操作数,而微指令在乱序执行引擎中只会携带指向操作数的指针,而非数据本身。这就大大降低了乱序执行硬件的功耗(转移大量数据很费电的),同时也减小了流水线的核心面积,数据流窗口也增大了三分之一。
核心面积的精简正是AVX指令(SNB最主要革新之一)集得以实现并保证良好性能的关键所在。以最小的核心面积代价,Intel将所有SIMD单元都转向了256-bit。AVX支持256-bit操作数,相当消耗晶体管与核心面积,而RPF的使用加大了乱序执行缓冲,能够很好地满足更高吞吐量的浮点引擎。
Nehalem架构中有三个执行端口和三个执行单元堆栈
SandyBridge允许256-bit AVX指令借用128-bit的整数SIMD数据路径,这就使用最小的核心面积实现了双倍的浮点吞吐量,每个时钟可以进行两个256-bit AVX操作。另外执行硬件和路径的上位128-bit是受电源栅极(Power Gate)控制的,标准128-bit SSE操作不会因为256-bit扩展而增加功耗。
AMD推土机架构对AVX的支持则有所不同,使用了两个128-bit SSE路径来合并成256-bit AVX操作,即使八核心(四模块)推土机的256-bit AVX吞吐量也要比四核心SNB少一半,不过实际影响完全取决于应用程序如何利用AVX。
SandyBridge的峰值浮点性能翻了一番,这就对载入和存储单元提出了更高要求。Nehalem/Westmere架构中有三个载入和存储端口:载入、存储地址、存储数据。
SandyBridge架构中载入和存储地址端口是对称的,都可以执行载入或者存储地址,载入带宽因此翻倍。SNB的整数执行也有了改进,只是比较有限。ADC指令吞吐量翻番,乘法运算可加速25%。
SandyBridge架构:环形总线与三级缓存
第三章/第六节 SandyBridge架构:环形总线与三级缓存 Nehalem/Westmere每个核心都与三级缓存单独相连,都需要大约1000条连线,而这种做法的缺点是如果频繁访问三级缓存,效果可能不会太好。
SandyBridge又整合了GPU图形核心、视频转码引擎,并共享三级缓存。Intel并没有沿用此前的做法,再增加2000条连线,而是像服务器版的Nehalem-EX、Westmere-EX那样,引入了环形总线(Ring Bus),每个核心、每一块三级缓存(LLC)、集成图形核心、媒体引擎、系统助手(System Agent)都在这条线上拥有自己的接入点,形象地说就是个“站台”。
SandyBridge的环形总线
这条环形总线由四条独立的环组成,分别是数据环(DT)、请求环(QT)、响应环(RSP)、侦听环(SNP)。每条环的每个站台在每个时钟周期内都能接受32字节数据,而且环的访问总会自动选择最短的路径,以缩短延迟。随着核心数量、缓存容量的增多,缓存带宽也随时同步增加,因而能够很好地扩展到更多核心、更大服务器集群。
这样,SandyBridge每个核心的三级缓存带宽都是96GB/s,堪比高端Westmere,而四核心系统更是能达到384GB/s,因为每个核心都在环上有一个接入点。
三级缓存的延迟也从大约36个周期减少到26-31个周期。此前预览的时候我们就已经感觉到了这一点,现在终于有了确切的数字。三级缓存现在被划分成多个区块,分别对应一个CPU核心,都在环形总线上有自己的接入点和完整缓存管线。每个核心都可以访问全部三级缓存,只是延迟不同。此前三级缓存只有一条缓存管线,所有核心的请求都必须通过它,现在很大程度上分而治之了。
和以前不同的是,三级缓存的频率现在也和核心频率同步,因而速度更快,不过缺点是三级缓存也会随着核心而降频,所以如果CPU降频的时候GPU又正好需要访问三级缓存,速度就慢下来了。





